
TL;DR
Running LLMs in production needs scalable system architecture. JDoodle.com combines cloud IDEs and online compilers (C, C++, Java, Python) to support developers building and testing AI at scale.
With the recent boom in LLMs, people in the AI/ML space are constantly looking for more efficient ways of running their LLMs.
In this post, I will explain the system architecture that can be used to achieve flexibility and efficiency in LLM ops.
Below are the system architecture and list of components that I will be suggesting to use for achieving cost-efficient and flexible infrastructure for your LLM loads:
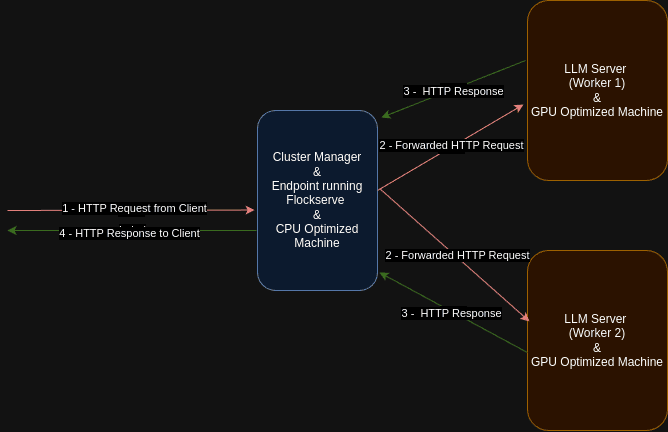
LLM Server
This is a regular GPU-optimized server for generating output from LLMs. Its properties are mainly set up through SkyPilot and potentially based on your custom logic, model, etc., to be used during the inference phase.
This typically includes the LLM inference optimization tools, such as TGI from Huggingface, TensorRT from Nvidia, vLLM, etc.
This part of the system is where we get a lot of options and interest in the community, so there are many tools for optimizing this bit of LLM inference ops. The Tensor/Model Parallelization, Paged attention, quantization, KV caching, etc. methods for running LLMs more efficiently on potentially multiple GPUs are all handled here by those external libraries.
I won’t get into the details of those methods. Instead, I will be focusing on system architecture-level decisions for LLM infrastructure, but below are some links for LLM Server Inference Tools you can use:
Cluster Manager
This is a CPU machine running the open-sourced tool FlockServe, which handles;
- Hardware provisioning using SkyPilot
- Load balancing between workers
- Omitting and passing the Telemetry data to our monitoring tools
- Storing input/output requests for Model performance monitoring and analysis.
Hardware provisioning using SkyPilot
One thing most of us would need to run our LLMs is powerful GPUs such as H100, A100, etc. it is only sometimes possible to easily find multiple of those GPUs quickly in one cloud provider.
It is even harder to find if you want to autoscale your LLM infrastructure when the load is high. To mitigate this issue, we use a tool called SkyPilot, which can scan multiple cloud providers and provide a GPU machine with the best available price. Currently, SkyPilot doesn’t support some of the well-known GPU providers like runpod.io and paperspace but provides access to all major cloud providers.
Load balancing between workers
FlockServe uses the below logic to balance the load between workers. This selects the work with the minimum number of active connections.
This is quite optimal as long as all the workers have the same capacity, but in cases where we want to run workers with different hardware or models, there might be better metrics to decide which worker to forward the request to.
At the moment, FlockServe only implemented LeastConnectionLoadBalancer, but we would be more than happy if you were keen to implement a different load balancer for FlockServe.
class LeastConnectionLoadBalancer(LoadBalancer):
"""
Selects the worker with the least number of queued tasks.
"""
def __init__(self, FlockServe):
super().__init__(FlockServe)
async def select_worker(self) -> WorkerHandler:
"""Selects the worker with the least number of connections."""
while True:
available_workers: List[WorkerHandler] = [
worker
for worker in self.FlockServe.worker_manager.worker_handlers
if WorkerManager.worker_available(worker)
]
if available_workers:
selected_worker = min(available_workers, key=lambda w: w.queue_length)
break
await asyncio.sleep(1)
return selected_worker
Omitting and passing the Telemetry data to our monitoring tools
Monitoring the latency, load, logs, etc., in real-time is necessary for a live system. Usually, cloud provider solutions like Google’s Vertex AI, AzureML, etc., handle those types of data collection and monitoring tasks.
In the proposed system architecture, we are not using any of the existing AI services of Cloud providers; instead, we just need VMs, so we implement the emission of telemetry data for monitoring our endpoint in FlockServe. This gives us quite a lot of flexibility in terms of the metrics, traces, and logs that are collected and also how and where we want to inspect them.
High-quality telemetry data is very helpful for measuring the performance of our worker nodes and worker managers. We can record custom metrics, monitor them, and set alarms based on them to identify real-time performance issues in our system.
There are two primary solutions embedded in FlockServe for Telemetry collection:
Running OTEL Collector — cloud-agnostic approach
FlockServe emits telemetry data by default. In this case, we are running an Open Telemetry Collector on the same machine that collects the emitted telemetry data and passes it to wherever you want to visualize it in real-time.
This is quite a flexible option, but the user needs to configure the OTEL Collector so that it passes the collected data to the target correctly.
Running Cloud Providers Collectors
This is where we let Cloud Providers’ collectors collect emitted telemetry from Flockserrve and use it with their monitoring services. This option is easier to set up but requires cloud-specific configurations.
Storing input/output requests for Model performance monitoring and analysis
There are only so many methods for assessing the quality of the LLM outputs, but they are all just summaries of the performance narrowed down to a single or a few numbers. This is only one of the issues when running an LLM in a production environment.
You are much more focused on cases that lead to failure rather than improving a decent output to an excellent one. I have seen some people call this fault-focused mindset, and it directly clicked in my mind.
As an AI engineer, we often eliminate cases where the output has hallucinations or some sort of issue like infinitely repeating tokens or just producing a way too long answer, which leads to a huge latency.
To identify those issues and propose potential solutions, we go through historical data of inputs and outputs.
Once we see a pattern in the historical data — For example, inputs longer than 32K leading to a repeating output — then we can propose solutions such as If the input is more extended than 32K tokens, then divide into two inputs and get the LLM to summarize that and combine first.
We can directly test this solution by applying it to the historical inputs and see if it is effective.
This is obviously a crucial and helpful ability for any system. It provides the opportunity to constantly improve your LLM outputs and develop a better understanding of them.
Comparing with Cloud Providers AI services
There are many alternative solutions from cloud providers such as Google Vertex AI, Azure Machine Learning, etc.
Those solutions provide pretty much the same abilities I have described above, and I will be comparing them with the FlockServe-based solution explained above:
Advantages of FlockServe over Cloud Provider Services
| Aspect | Advantage 1 | Advantage 2 |
|---|---|---|
| Cost | Because we only use VMs, there is only a minimal cost of hardware use. | Skypilot provides the advantage of finding the cheapest available GPU in the cloud providers of your choice. |
| Flexibility | Can use hardware from different cloud providers simultaneously and switch between them on the fly. | Control over every part of the system. As FlockServe is an open-source project and the infrastructure only consists of VMs, you have complete control over each part of the system. |
| Cloud Agnostic -- No vendor lock-in | Changing the cloud provider for this infrastructure is as easy as adding or removing the names of cloud providers from a list. | All system parts are cloud-agnostic and require zero effort to switch between providers. |
| Disadvantages | Require more engineering effort & knowledge | As usual in most software, more control comes with the requirement of knowledge and effort. This is no different from the proposed system architecture here. This requires a deeper understanding of LLM Ops and requires more effort to get things done the way best fits your needs. |
Conclusion
We have walked through a system architecture for running LLMs and compared it with the AI services of cloud providers. The proposed architecture provides a more flexible and efficient way of running LLMs with the cost of extra engineering effort.
FAQs (Frequently Asked Question)
1. What is system architecture for LLMs?
It is the setup of hardware and software needed to run large language models (LLMs) efficiently in production.
2. Can I run LLMs using online compilers?
Not directly, but platforms like JDoodle.com combine online compilers with scalable cloud setups to support AI workloads.
3. How does a Python compiler help with LLM workloads?
A Python online compiler is often used to test and run LLM-related code. JDoodle’s Python compiler makes it easy for developers to prototype and validate AI models quickly.
4. How does JDoodle help developers with LLM workloads?
JDoodle offers online C, C++, Java, and Python compilers along with cloud resources that support AI and LLM testing.
5. Are cloud IDEs useful for AI development?
Yes, cloud IDEs with online compilers like JDoodle make it easy to test and run code while connecting to AI frameworks.